TRAITEMENT D'IMAGES SUR GPU
Algorithmes parrallèles rapides pour le filtrage et la segmentation des images bruitées sur GPU.
Gilles Perrot
Université de Franche-Comté, Institut FEMTO-ST
Département DISC - équipe AND
PLAN DE LA PRÉSENTATION
- Introduction - cadre des travaux
- Les GPUs (Graphical Processing Units)
- Généralités sur le traitement d'image. Nos axes de recherche.
- La segmentation des images
- Généralités. Travaux de référence.
- Parallélisation GPU d'un algorithme de segmentation de type snake.
- Le filtrage des images
- Généralités. Travaux de référence.
- Optimisation pour GPU des filtres médian et de convolution.
- Conception d'un algorithme parallèle de réduction de bruit par recherche des lignes de niveaux.
- Synthèse et conclusion.
INTRODUCTION
INTRODUCTION
Les GPUs ou Processeurs graphiques.
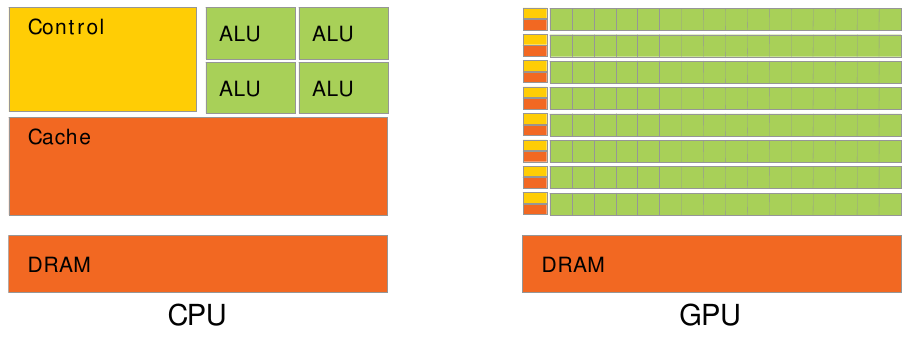
- Processeurs classiques CPU : exécution séquentielle
- Quelques unités de calcul ( les cœurs).
- Processeurs graphiques GPU : exécution massivement parallèle
- Des centaines, voire millier, d'unités de calcul, regroupées en quelques SMs (Streaming Multiprocessors).
INTRODUCTION
Les GPUs ou Processeurs graphiques.
- La multiplication des cœurs dans les GPUs se fait au détriment des fonctions de contrôle et de cache.
- Seule la mémoire globale est accessible par l'ensemble des fils d'exécution (les threads) et ses performances sont faibles.
- L'accès efficace aux différents types de mémoires est contraignant.
- Les échanges de données entre le GPU et son hôte CPU sont pénalisants.
- Il est important de concevoir un partage équilibré des ressources au sein de chaque SM, pour permettre un niveau de parallélisme élevé, et donc d'envisager de bonnes performances.
- La mise au point n'est pas aisée lorsque des centaines de milliers de threads concourent à l'exécution d'une tâche.
INTRODUCTION
Le traitement des images
- Beaucoup d'applications sont basées sur l'analyse ou la visualisation d'images numériques.
- Les capteurs numériques et les conditions d'acquisition sont à l'origine de perturbations (bruits) qui dégradent l'image de la scène idéale et peuvent en fausser ou compliquer l'interprétation.
- La réduction de bruit demeure un thème important, car les hautes résolutions sont souvent obtenues à faible flux de photons, dont les variations engendrent du bruit.
- La segmentation représente aussi un enjeu crucial, mais aucun algorithme universel n'a encore été élaboré.
- on recense plus de 4000 algorithmes de segmentation
- La segmentation intervient dans beaucoup d'applications : du tracking à la détection ou à l'extraction de caractéristiques diverses.
- Mais aujourd'hui encore, une bonne segmentation est celle qui permet d'extraire ce que l'on attend => l'algorithme dépend du problème.
INTRODUCTION
Le traitement des images
- L'accroissement des capacités de calcul a suivi l'augmentation des résolutions d'images.
- Les traitements envisagés sur les images sont de plus en plus évolués ( traitements de haut niveau ) et requièrent souvent un temps de calcul accru.
- L'architecture parallèle particulière des GPUs a permis d'améliorer considérablement les performances de certaines classes d'algorithme et fait espérer des accélérations importantes pour d'autres.
Nos travaux sont une contribution à cette recherche de performance.
- La croissance des capacités de calcul des GPUs à été beaucoup plus forte que celle des CPUs.
INTRODUCTION
Traitements d'images de haut niveau
- Pré-traiter et effectuer les traitements de haut niveau sur des images améliorées.
- permet, a priori, de réduire le coût des traitements de haut niveau.
- les prétraitements ont eux aussi un coût, en temps de calcul et potentiellement en information.
- Ne pas pré-traiter et effectuer les traitements de haut niveau sur les images bruitées.
- permet de ne pas subir la perte d'information occasionnée par le pré-traitement.
- les traitements de haut niveau sont, a priori, plus coûteux.
Certains algo (LNIV) peuvent être considérés comme pré-traitement ou comme haut-niveau selon le point de vue et la classe d'algorithme.
INTRODUCTION
Axes des travaux présentés
Segmentation : accélérer le traitement de haut niveau
- La segmentation consiste à identifier des zones homogènes dans une image.
- Algorithme de segmentation d'images bruitées (fortement) par contours actifs, appartenant à la classe communément appelée snakes.
Filtrage : accélérer les pré-traitements
Réduction de bruit additif gaussien, suivant deux méthodes de conception :
- algorithme original, conçu spécifiquement pour GPU, conjointement à son implémentation.
- algorithmes existants, où l'effort de conception ne peut porter que sur l'implémentation : filtres médian et de convolution.
INTRODUCTION
Images traitées
- Nous nous sommes focalisés sur les images naturelles :
- réalisées en lumière naturelle, en intérieur aussi bien qu'en extérieur,
- prises avec un dispositif standard (CMOS, CCD).
- Les traitements que nous présentons ici opèrent sur des images en niveau de gris (8 ou 16 bits).
Toutefois, la plupart des algorithmes que nous proposons s'étend simplement à d'autres types d'images, comme les images en couleur ou celles issues des imageries ultrasonore ou RADAR à ouverture synthétique.
LA SEGMENTATION DES IMAGES
Segmentation par contour actif
SEGMENTATION PAR CONTOUR ACTIF
Introduction
- Le domaine médical recèle la quasi totalité des implémentations GPU d'algorithmes de segmentation.
- Nombre d'entre elles concernent des traitements effectués en 3D par nécessité, où l'emploi du GPU s'impose assez naturellement.
- La segmentation par contour actif regroupe des méthodes itératives tendant à faire converger, par déformation successive, une courbe paramétrique (contour) selon un critère d'homogénéité pré-établi :
- La classe d'algorithmes la plus implémentée est celle des level-set, essentiellement dans sa variante bande étroite.
- La classe des snakes n'est implémentée qu'au travers la variante GVF (Gradient Vector Flow).
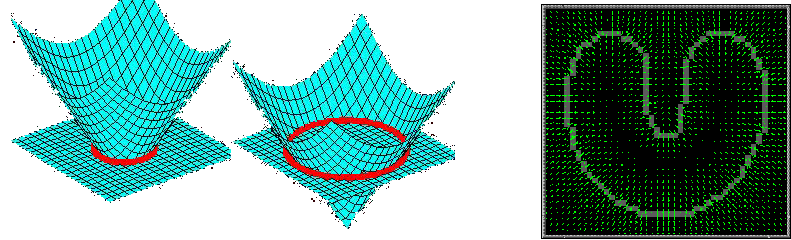 À gauche : Level-set, évolution du contour, en rouge. À droite : visualisation du champ de force d'un snake GVF.
À gauche : Level-set, évolution du contour, en rouge. À droite : visualisation du champ de force d'un snake GVF.SEGMENTATION PAR CONTOUR ACTIF
Travaux de référence (level-set)
L'implémentation de Roberts et al. du level-set à bande étroite est actuellement la plus performante et parvient à segmenter des images d'IRM
- 3D, de 256x256x256 pixels, sur GTX280, en 11 000 ms
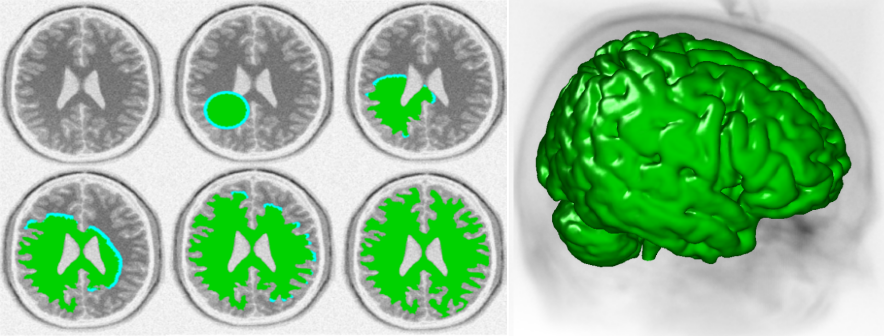 À gauche : évolution du contour pour une tranche avec, en bleu, les zones actives. À droite : visualisation en 3D de la segmentation complète.
À gauche : évolution du contour pour une tranche avec, en bleu, les zones actives. À droite : visualisation en 3D de la segmentation complète.SEGMENTATION PAR CONTOUR ACTIF
Travaux de référence (snake)
- À notre connaissance, aucune publication ne décrit d'implémentation de snake polygonal ou de snake orienté région.
- La référence est l'implémentation snake GVF de Smistad et al. qui parvient à segmenter des images d'IRM
- 2D, de 512x512 pixels, sur C2070, en 41 ms.
- 3D, de 256x256x256 pixels, sur C2070, en 7151 ms
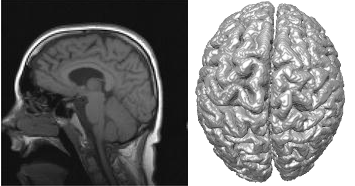 À gauche : une image 2D d'IRM. À droite : visualisation en 3D de la segmentation complète.
À gauche : une image 2D d'IRM. À droite : visualisation en 3D de la segmentation complète.SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (principe)
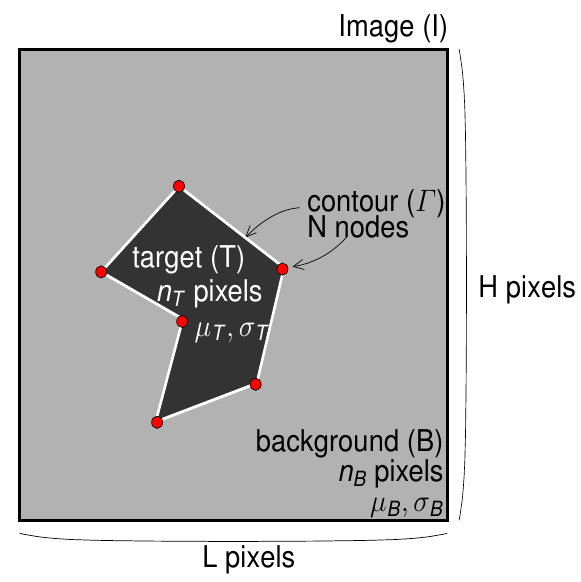 |
|
- Les deux régions, intérieure et extérieure (T et B), sont prises en compte dans l'évaluation du contour. Cela permet d'extraire des formes aux contours mal définis, en raison d'un fort niveau de bruit par exemple.
- Les variances \(\sigma^2\) doivent être calculées pour chaque état du contour, ce qui est très coûteux.
SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (principe)
- Chesnaud et al. ont montré comment réaliser le calcul des variances par une sommation 2D le long du contour, au lieu d'une classique sommation 3D sur la surface des régions concernées.
- Cette optimisation algorithmique implique de pré-calculer les trois images cumulées$$S_1(i,j)=\sum_{x=0}^jx \text{ , } S_x(i,j)=\sum_{x=0}^jI(i,x) \text{ et } S_x^2(i,j)=\sum_{x=0}^jI(i,x)^2$$
- Les valeurs des éléments de ces images cumulées permettent de calculer la contribution de chaque pixel du contour, puis de chaque segment, aux calculs des variances.
SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (algo CPU)
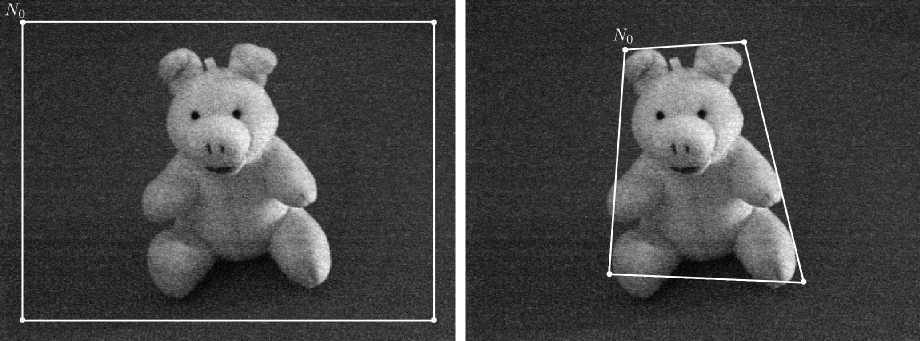
Itération 1
- Le contour initial est rectangulaire ( 4 nœuds )
- On déplace successivement les 4 nœuds jusqu'à ce que plus aucun nouveau déplacement ne provoque l'amélioration du critère.
SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (algo CPU)
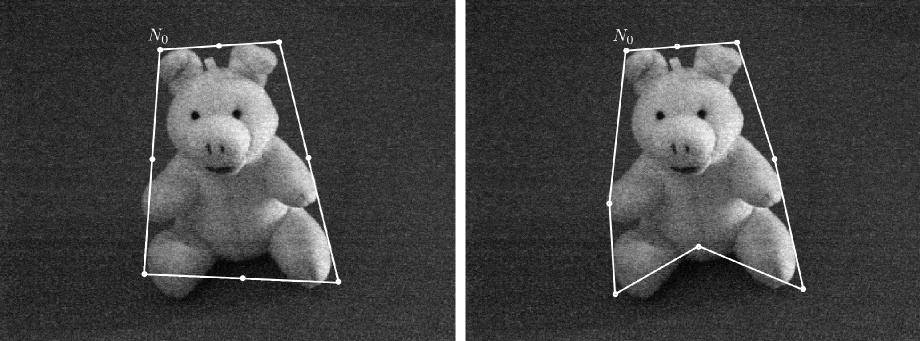
Itération 2
- Ajout de nœuds au milieu des segments suffisamment grands.
- On recommence à évaluer les déplacements successifs des nœuds.
SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (algo CPU)
Itérations 4 et 5
SEGMENTATION PAR CONTOUR ACTIF
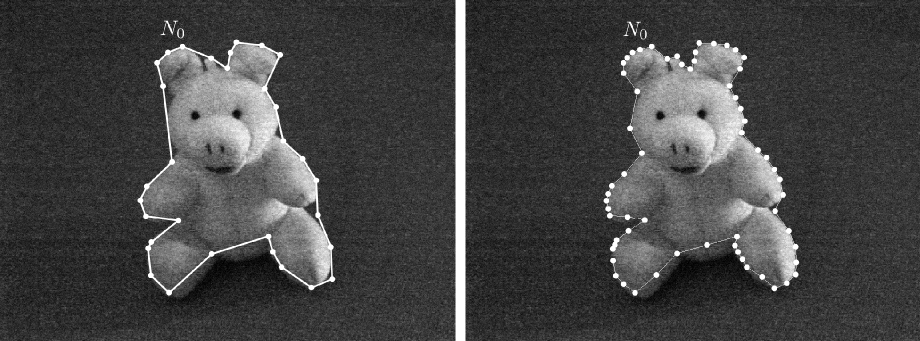
Snake polygonal orienté région (algo CPU)
 Image de 512x512 : contour final de 256 nœuds en 14ms.
Image de 512x512 : contour final de 256 nœuds en 14ms.- Les résultats de segmentation dépendent des paramètres de la séquence d'optimisation (pas des déplacements, contour initial, seuil d'ajout des nœuds)
SEGMENTATION PAR CONTOUR ACTIF
Snake polygonal orienté région (algo CPU)
 Image de 4000x4000 : contour final de 447 nœuds en 700ms.
Image de 4000x4000 : contour final de 447 nœuds en 700ms.SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Identification des fonctions coûteuses
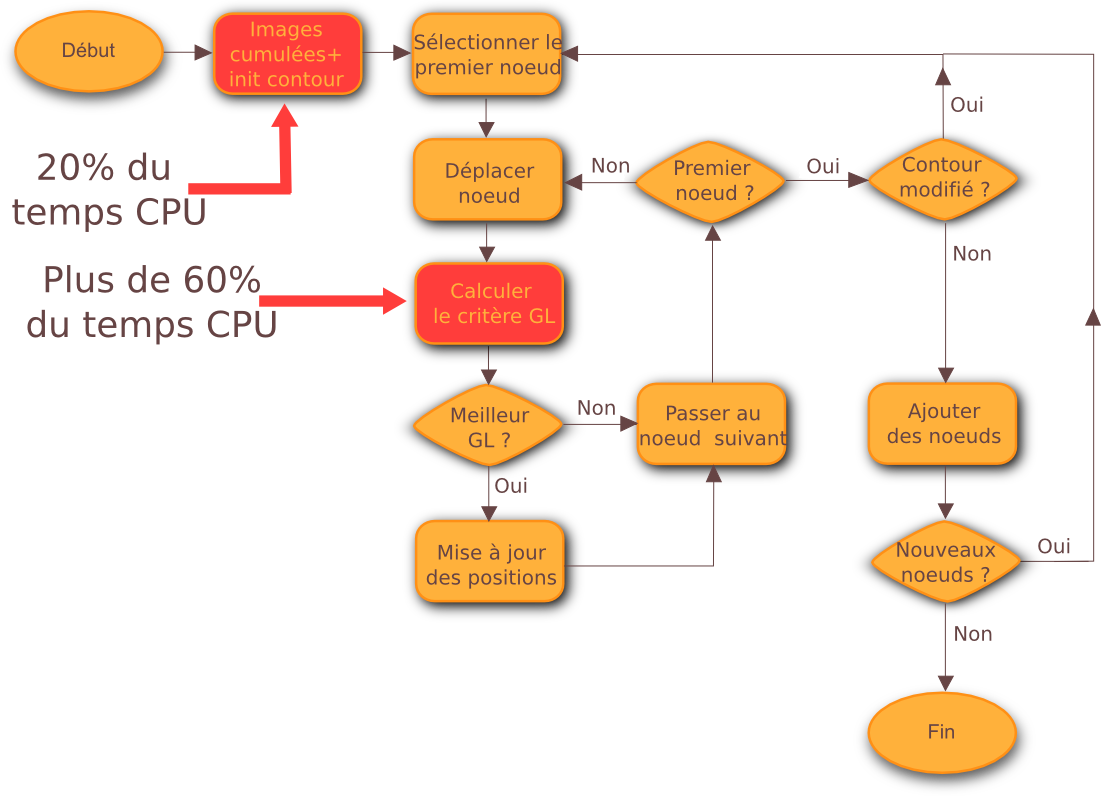
SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Détail de la fonction de calcul du critère GL
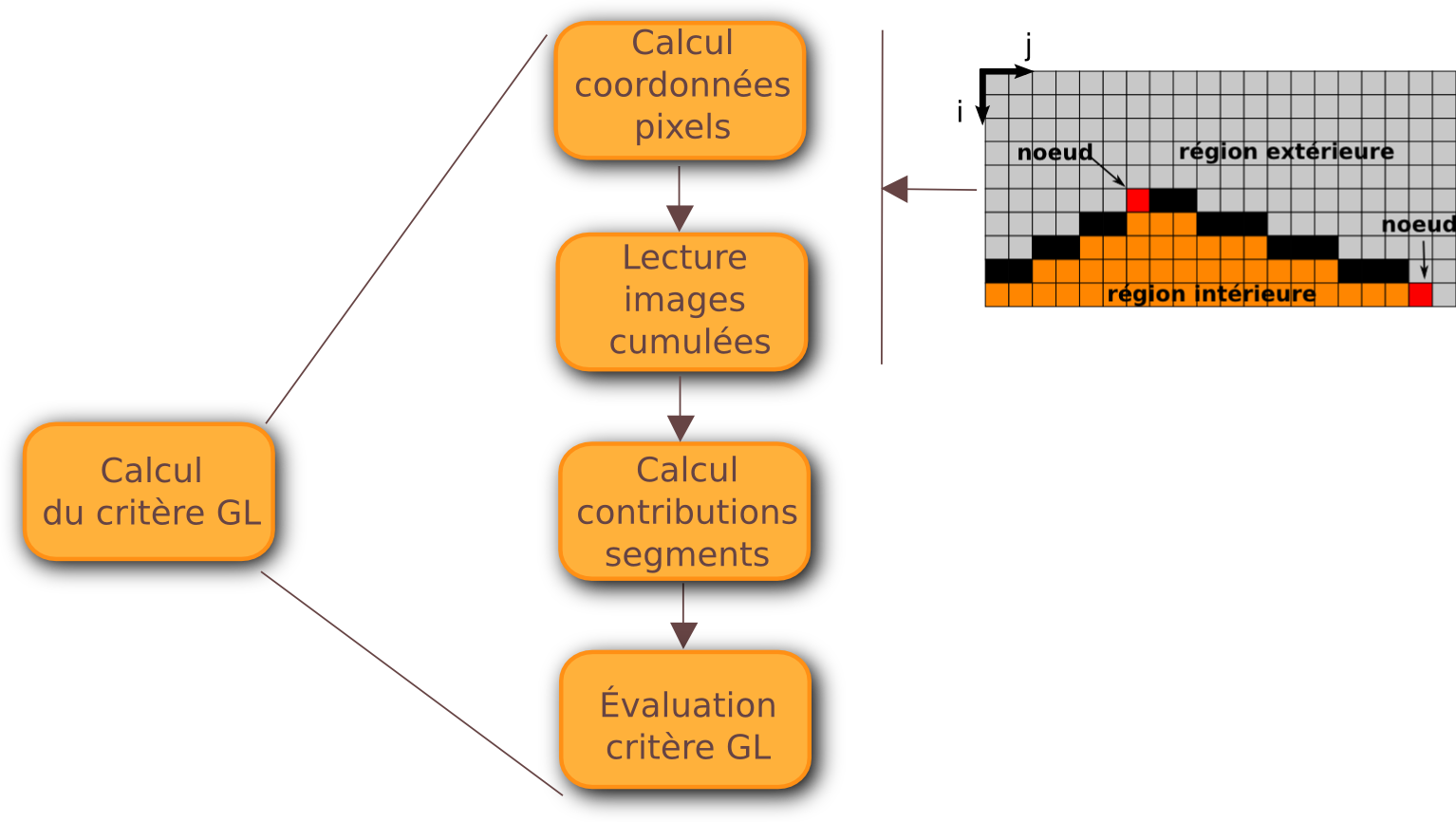
SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
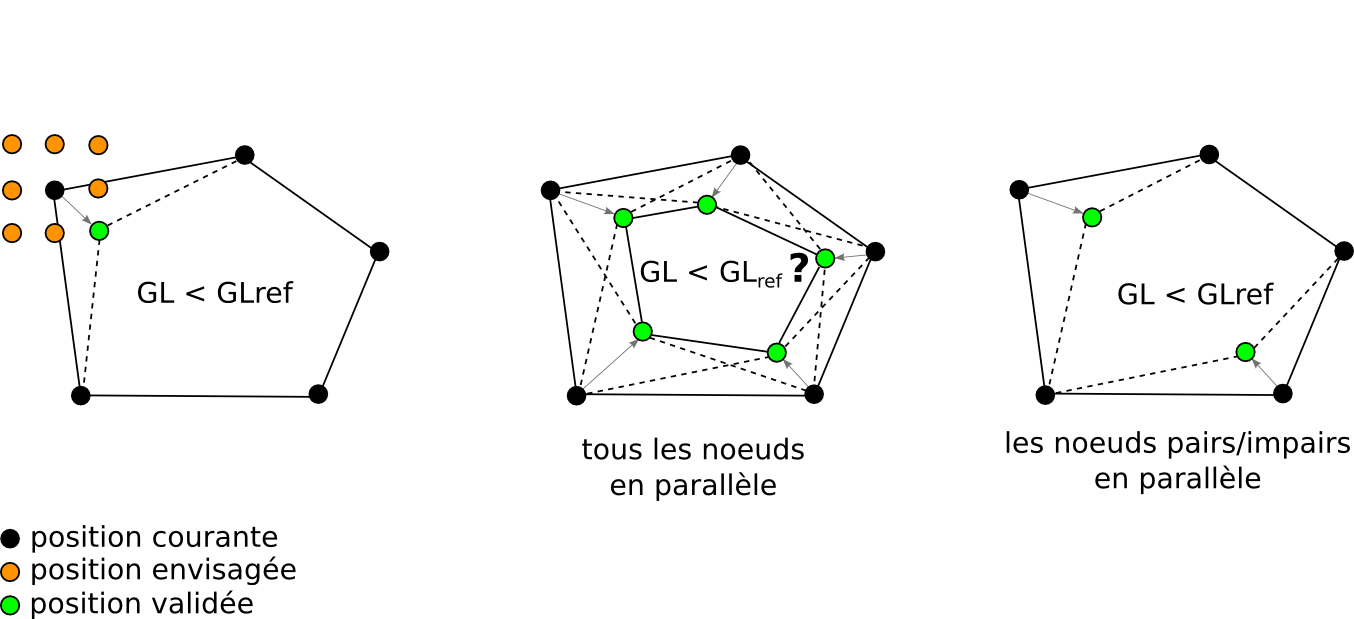
- Pour un nœud et un pas de déplacement donnés, on évalue en parallèle 8 positions voisines, soit 16 segments distincts.
- Pour éviter les oscillations et coller à l'algorithme séquentiel, on distingue les nœuds d'indices pairs et impairs.
- On évalue en parallèle l'ensemble des déplacements éventuels de tous les nœuds de même parité.
SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Structure des données (nœuds pairs)
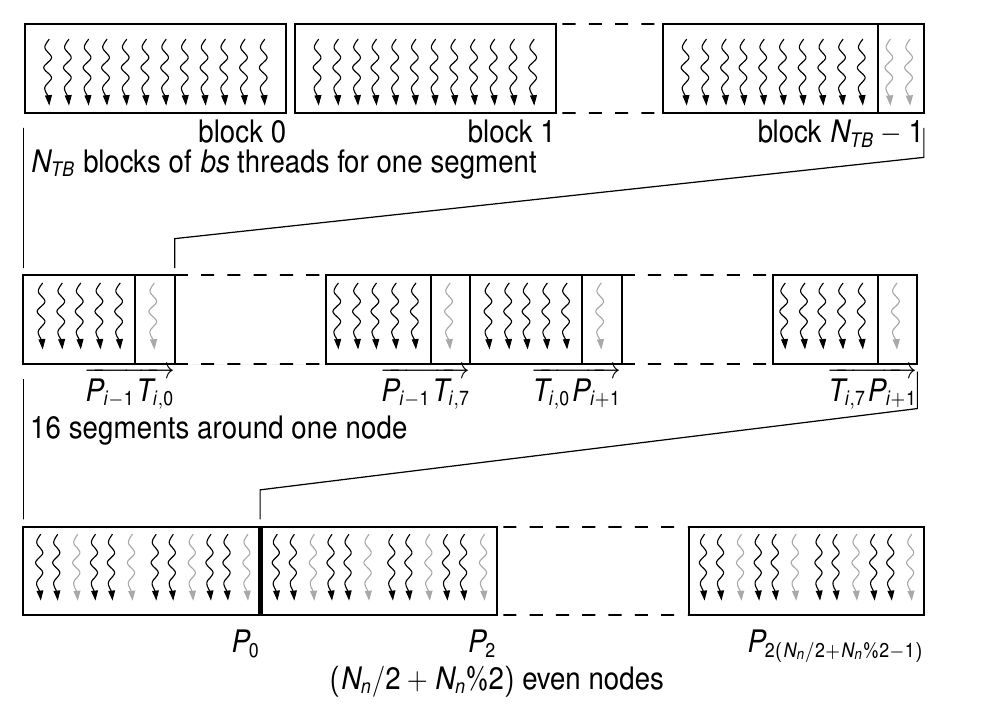
- règle 1 thread par pixel
SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Obtention du critère
- Parallélisation : 1 thread par pixel.
- Une seule taille de segment : la taille du plus long.
- Bourrage avec des threads inactifs pour les segments plus courts.
- Calcul réalisé en 3 étapes par 3 fonctions parallèles GPU (kernels)
- Calcul des coordonnées des pixels. Lecture des paramètres de chaque pixel dans les images cumulées. Sommes partielles, par bloc, des contributions des segments.
- Calcul final des contributions des segments par sommation des résultats du kernel précedent.
- Calcul des valeurs du critère pour chaque contour évalué. Sélection du meilleur contour.
SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Propriétés de l'implémentation
- Conservation des données en mémoire GPU.
- Les images cumulées sont calculées en parallèle.
- Abandon de l'algorithme de Bresenham pour la discretisation des segments.
- Trop peu de calculs à effectuer.
- Pas de coalescence possible dans les accès à la mémoire globale.
- Emploi de la mémoire partagée.
- Un seul entier est échangé entre le CPU et le GPU à chaque itération.
- image cumulées par une adaptation de la méthode des sommes de préfixes.
- Abandon Bresenham Possible car parcours unidirectionnel du contour.
- Trop peu de calculs ne permet pas de masquer les latences.
- Pas de coalescence possible dans les accès à la mémoire globale car la géométrie des segments varie.
- mémoire partagée à cause des réductions.
SEGMENTATION PAR CONTOUR ACTIF
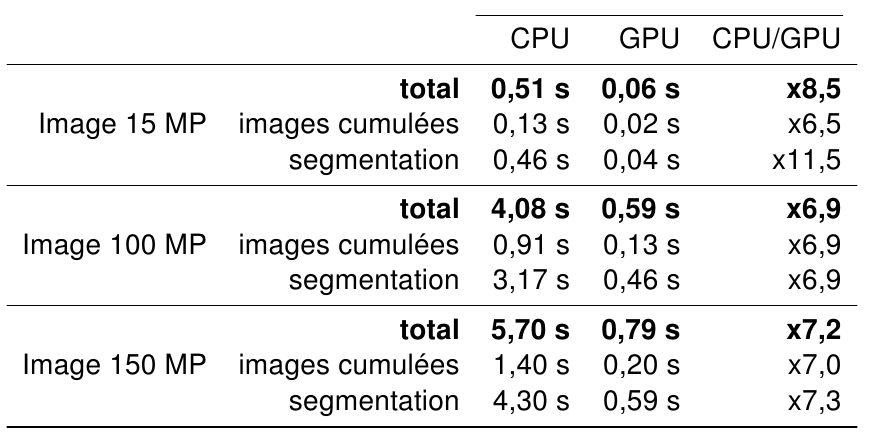
Parallélisation du Snake polygonal sur GPU
Performances de l'implémentation

SEGMENTATION PAR CONTOUR ACTIF
Parallélisation du Snake polygonal sur GPU
Conclusion
- Première et seule implémentation à ce jour.
- Performances intéressantes pour les grandes images. 1OO MP en moins de 0,6 seconde.
- Temps de calcul très dépendant du contenu de l'image.
- Le GPU n'est pas employé de manière optimale : réductions, threads inactifs, non coalescence.
- Le GPU apporte un gain important sur les premières itérations, quand les segments sont grands.
- Initialisation optionnelle par maximum de vraisemblance. Accélération jusqu'à x15 avec de petites cibles.
LE FILTRAGE DES IMAGES
Filtre médian - Filtres de convolution - Filtre par lignes de niveaux
LE FILTRAGE DES IMAGES
Filtre médian
LE FILTRAGE DES IMAGES
Filtre médian : principe
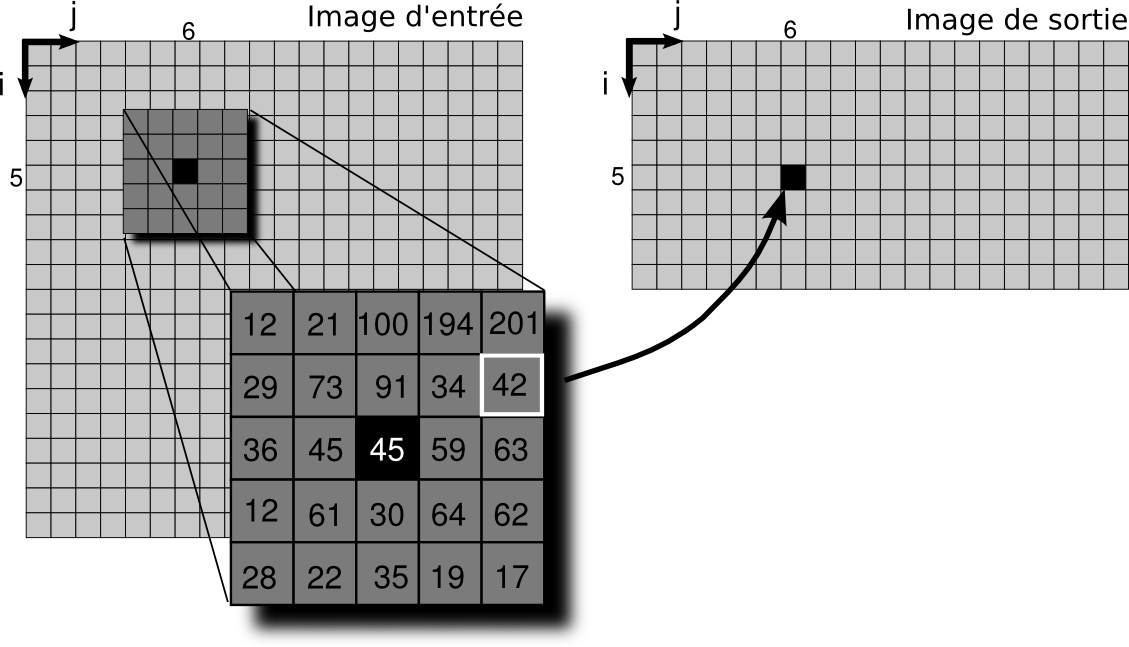
La valeur de sortie d'un pixel est la médiane des valeurs de son voisinage.
- Bonne réduction de bruits gaussien et poivre & sel
- Valeurs de sortie appartenant au voisinage.
- Opération de sélection coûteuse (tri).
- Usages fréquents avec des petites fenêtres (de 3x3 à 7x7).
- Quelques applications avec de grandes fenêtres (au delà de 21x21).
LE FILTRAGE DES IMAGES
Filtre médian : usage
 |  |  |
|---|---|---|
Bruit poivre & sel 25% | Médian 5x5 | Médian 3x3 - 2 passes |
LE FILTRAGE DES IMAGES
Filtre médian GPU : Travaux de référence
- Sanchez et al. ont proposé le PCMF et l'ont comparé, sur C2075, avec les implémentations GPU de référence pour une image 8 bits de 512x512 (débit max. 80 MP/s) :
- ArrayFire, bibliothèque commerciale, débit max. 185 MP/s
- BVM parallélisé par Kachelrieß, débit max. 110 MP/s
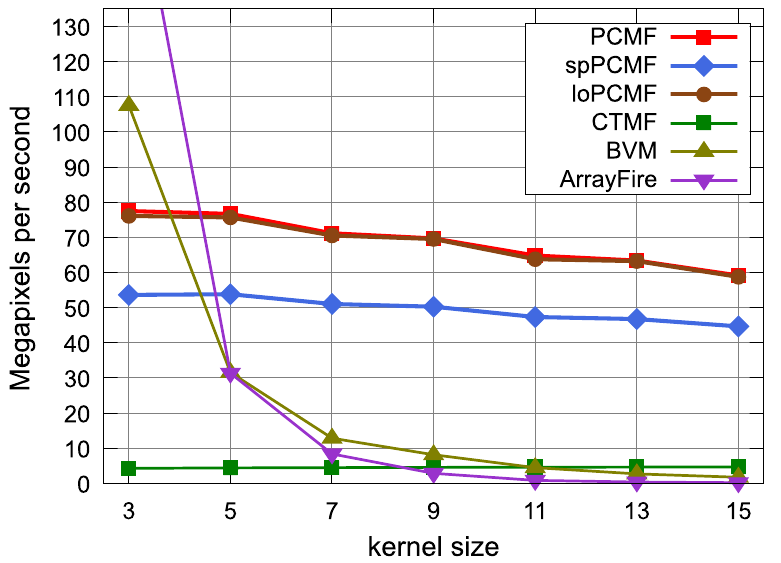
- PCMF : Parallel (Complementary Cumulative Derivative Function) Median Filter (histogrammes cumulatifs)
- CTMF : CPU à temps constant
LE FILTRAGE DES IMAGES
Filtre médian GPU : Travaux de référence
Emploi de la mémoire partagée pour pré-charger les valeurs utiles à chaque bloc de threads.
LE FILTRAGE DES IMAGES
Optimisation du filtre médian GPU
Transferts des données optimisés
CPU \(\rightarrow\) GPU texture :KERNEL: GPU globale \(\rightarrow\) CPU non paginée
On gagne de 13 à 43 % sur les temps de transfert.
LE FILTRAGE DES IMAGES
Optimisation du filtre médian GPU
Débits maximums effectifs, en MP/s, pour des images en 8 et 16 bits, incluant les transferts optimisés (C2070).
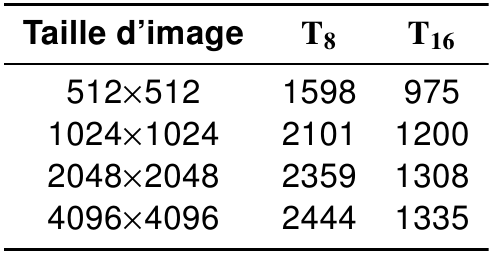
Rappel : PCMF : 80 MP/s - BVM : 110 MP/s - ArrayFire : 185 MP/s
ça laisse environ 80ms pour faire un tri de 9 valeurs sur une image de 4096x4096
LE FILTRAGE DES IMAGES
Optimisation du filtre médian GPU
Sélection de la médiane
- Emploi exclusif des registres pour charger les valeurs utiles.
- Limitations à 63 registres par thread et 32 K par bloc de threads.
- Envisageable pour les médians de petite taille (jusqu'à 7x7 avec 1 thread/pixel).
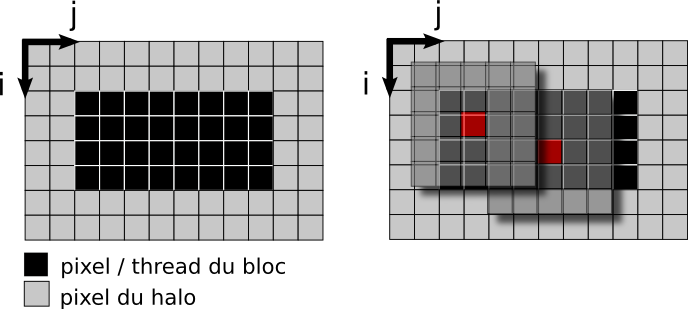
- Exploitation des recouvrements entre fenêtres de pixels voisins.
LE FILTRAGE DES IMAGES
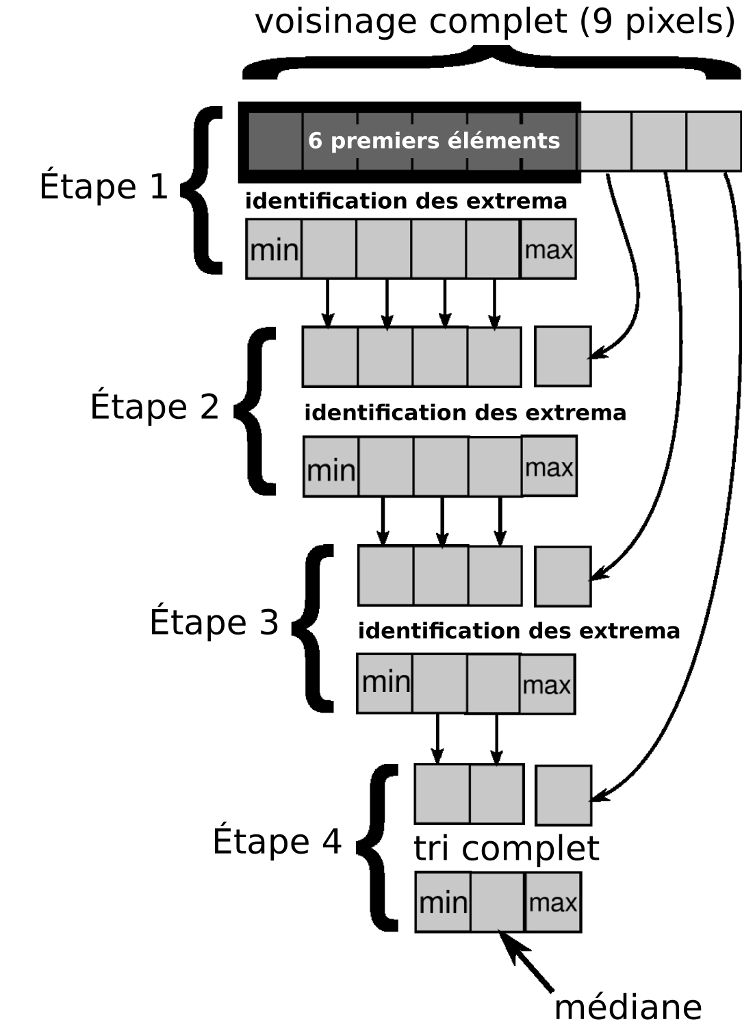
Optimisation du filtre médian GPU
Sélection de la médiane (par oubli)
Bonnes performances envisagées :
|  |
LE FILTRAGE DES IMAGES
Optimisation du filtre médian GPU
Exploitation des recouvrements
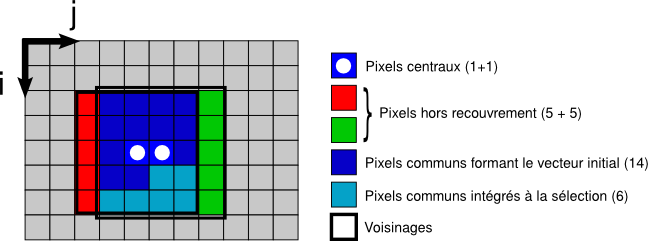
Intérêt : Économie de registres - chaque thread traite 2 pixels.
- chaque thread utilise plus de registres
- mais sur un bloc, en adaptant la taille du bloc, on économise k+1 registres par paire de pixels.
LE FILTRAGE DES IMAGES
Optimisation du filtre médian GPU
Masquage des latences
- Accès à la mémoire globale : 2 pixels par thread.
- Instruction Level Parallelism (ILP) : Ordre des instructions minimisant l'interdépendance.
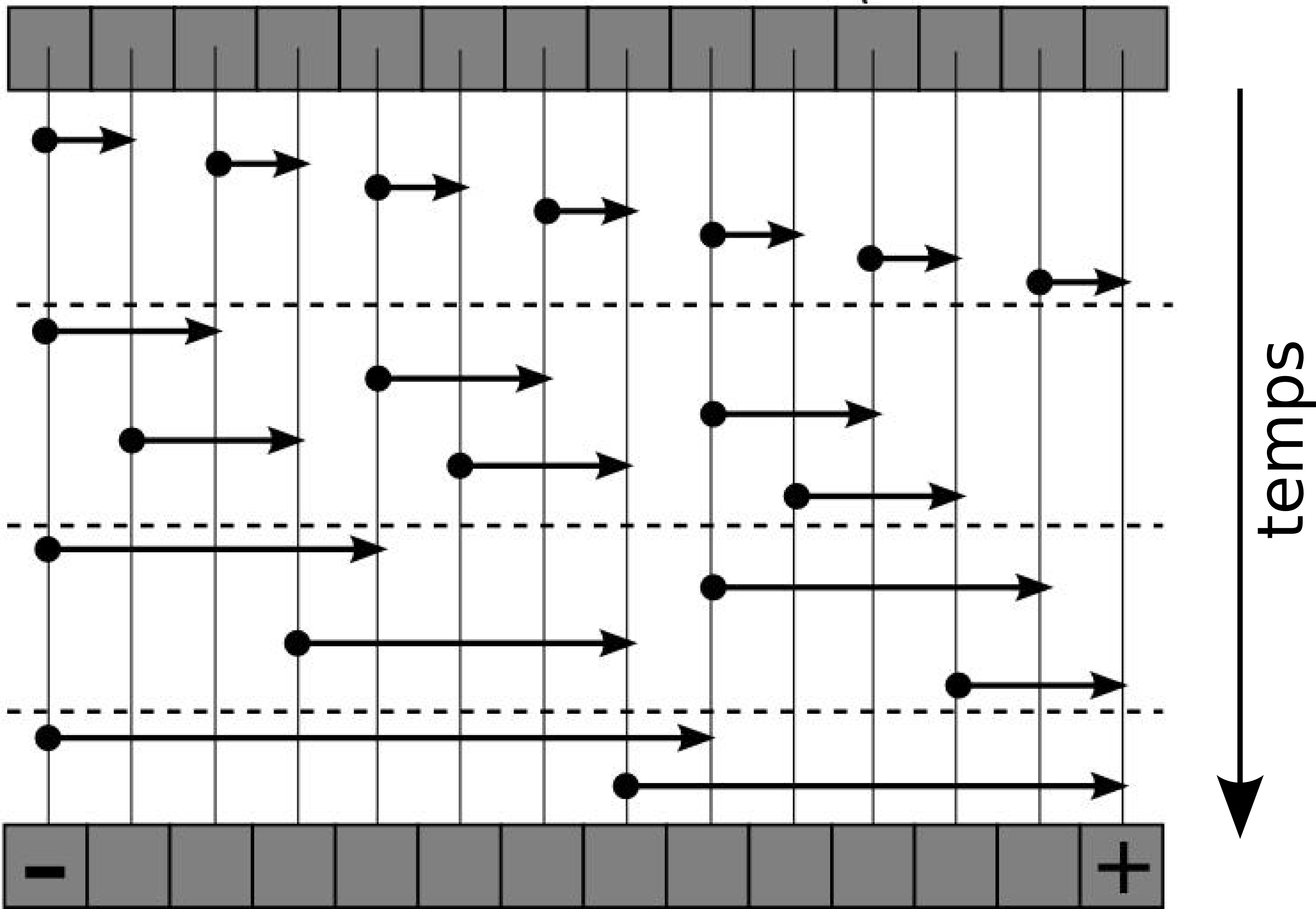 Identification des extrema dans le vecteur initial d'un médian 5x5
Identification des extrema dans le vecteur initial d'un médian 5x5
- au delà de 2 pixels par thread, le gain sur les latences est compensé par la perte sur le calcul / niveau de parallèlisme.
- ILP maximisée en appliquant une méthode simple; utilisée par ex. dans la technique des réseaux de tri bitoniques.
LE FILTRAGE DES IMAGES
Performances du filtre médian GPU proposé (PRMF)
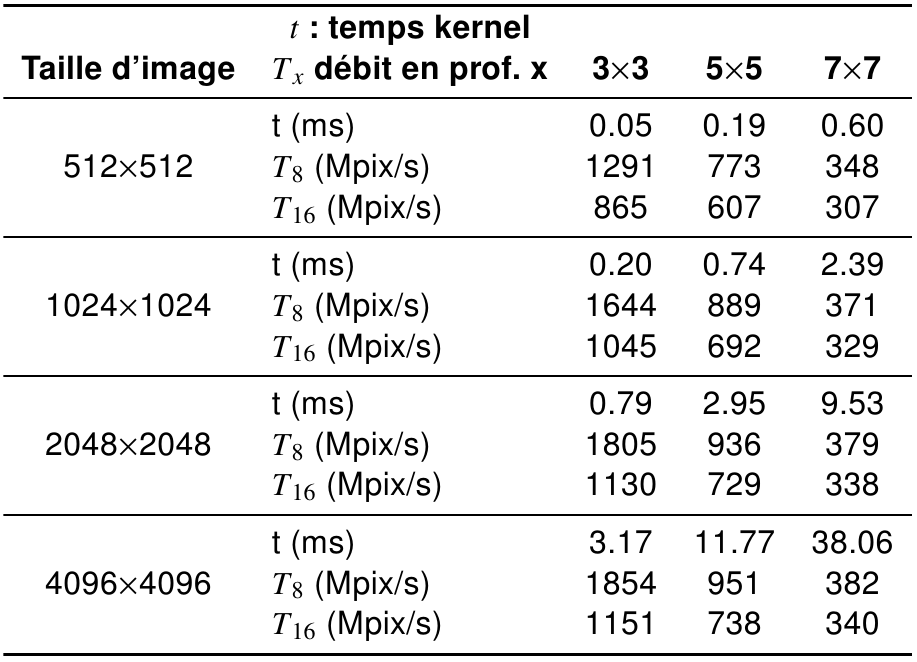
LE FILTRAGE DES IMAGES
Performances du filtre médian GPU proposé (PRMF)
Image 512x512
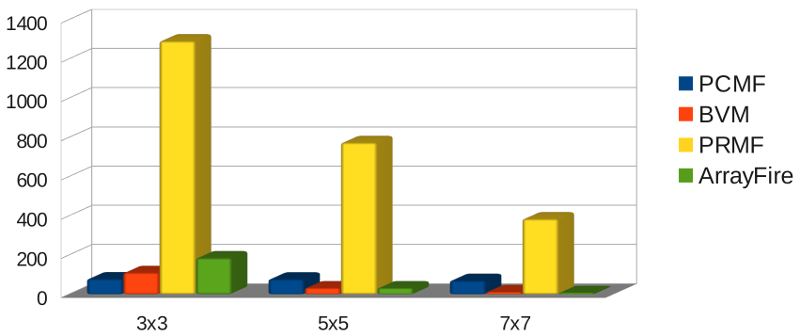
Image 4096x4096
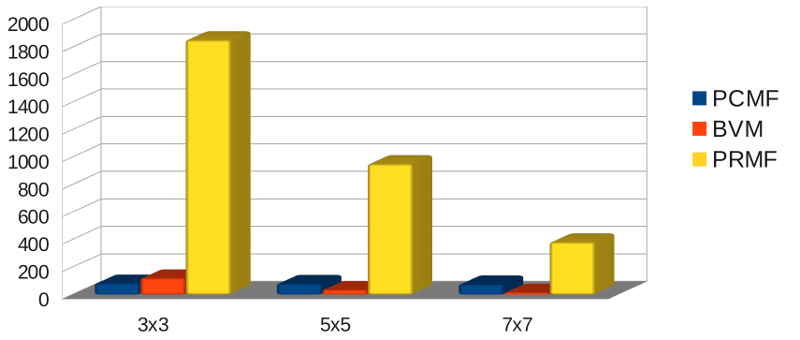
LE FILTRAGE DES IMAGES
Le filtre médian GPU
Conclusion
- Pas d'utilisation de la mémoire partagée.
- Débit global amélioré de x7 à x10, proche du maximum.
- Débit de calcul atteignant 5,3 GP/s.
- Médian jusqu'au 9x9 sur C2070, 21x21 sur K40.
- Création d'une application web générant les codes sources.
- Utilisé pour le pré-traitement d'images de cristallographie au synchrotron SPring-8 (Japon).

LE FILTRAGE DES IMAGES
Les filtres de convolution
LE FILTRAGE DES IMAGES
Les filtres de convolution : généralités
Principe
$$I_{out}(x, y) = \left(I_{in} * h\right) = \sum_{(i < H)} \sum_{(j < L)}I_{in}(x-j, y-i)h(j,i)$$
Usage, selon les valeurs du masque h
- réduction de bruit,
- détection de bords,...
- selon h --> convo séparable ou non séparable
LE FILTRAGE DES IMAGES
Les filtres de convolution GPU
Le fabricant Nvidia propose la plus rapide des implémentations connue :
Convolution non séparable sur image de 2048x2048, masque h de 5x5, sur GTX280.
- Débit global : 945 MP/s.
- Débit de calcul : 3,00 GP/s
LE FILTRAGE DES IMAGES
Les filtres de convolution GPU
Exploitation des recouvrements
- un seul accès mémoire par pixel, mémorisation en registre.
- mise à jour de tous les calculs concernés
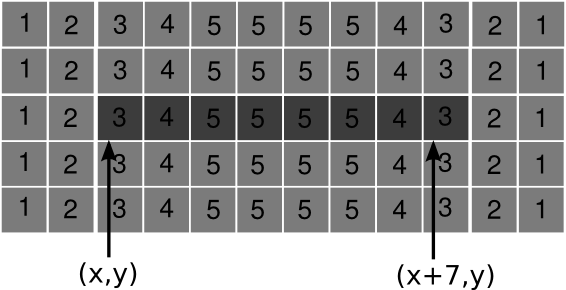
Application des techniques présentées pour le filtre médian :
- Optimum à 8 pixels par thread.
- Débit global : 966 MP/s.
- Débit de calcul : 3,47 GP/s
Sur C2070, nos débits sont de 1666 MP/S et 5280 MP/s. Les débits maximum atteignent 2140 MP/s et 8540 MP/s (4090x4096, masque 3x3)
LE FILTRAGE DES IMAGES
Les filtres de convolution GPU
Convolution séparable sur C2070.
Implémentation Nvidia (mémoire partagée)
- Débit global max : 1933 MP/s.
- Débit de calcul max : 6000 MP/s
Notre implémentation
- Optimum à 8 pixels par thread.
- Une convolution 1D en mémoire partagée, l'autre en registres. Copie intermédiaire en mémoire globale (cache 1D rapide).
- Débit global : 2028 MP/s.
- Débit de calcul : 7626 MP/s
- Le gain est obtenu sur la convolution 1D en registres.
LE FILTRAGE DES IMAGES
Les filtres de convolution GPU
Conclusion
- Amélioration limitée des débits globaux en raison de la prépondérance des temps de transfert.
- Amélioration sensible sur les débits de calcul (de 17 à 33 %).
- Le traitement 1D est jusqu'à 66% plus rapide. Applicable à d'autres signaux 1D.
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Motivations :
- Les algorithmes qui débruitent le mieux sont lents (BM3D).
- Les images naturelles sont décomposables en un ensemble de lignes de niveaux ( iso-niveau de gris ).
- Concevoir un algorithme GPU original et son implémentation.
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Principe
- Estimation locale, par maximum de vraisemblance, des lignes de niveaux.
- Réduction de bruit par moyennage le long de la ligne estimée.
- Les lignes de niveaux estimées sont modélisées par des lignes brisées nommées isolines.
- Les segments des lignes brisées sont choisis parmi des motifs pré-établis (32 motifs).
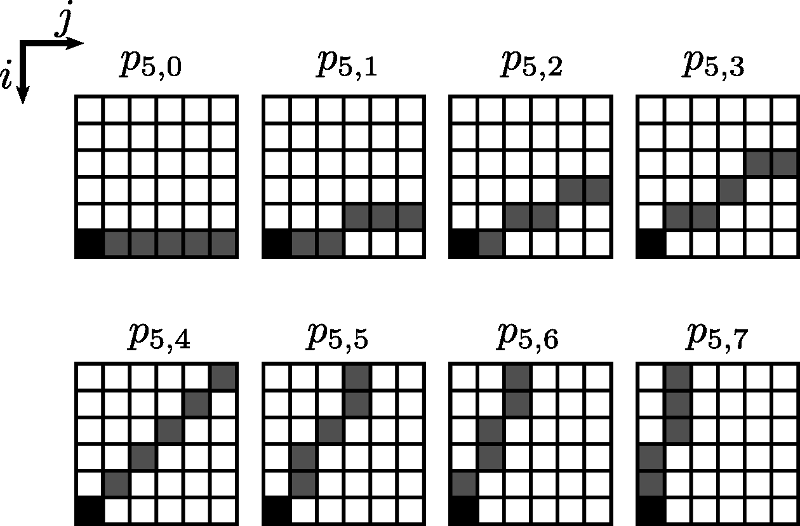
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Principe (étape 1)
$$-\frac{n}{2}log\left(2\pi\right) - \frac{n}{2}log\left(\sigma^2\right) - \frac{n}{2}$$
- En chaque pixel, recherche du motif maximisant la log-vraisemblance ( \(n=6, \sigma^2 =\) variance )
- Mémorisation des paramètres des motifs sélectionnés dans deux matrices \(I_{\Theta}\) et \(I_{\Sigma}\).

LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Principe (étape 2)
$$(n_{s_1s_2}+n_{s_3})\left[log\left(\widehat{\sigma_{s_1s_2}}^2\right) - log\left(\widehat{\sigma_{s_3}}^2\right) \right]$$
- Allongement itératif des segments sous condition GLRT.

LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Principe (étape 3)
Compensation de la non robustesse de sélection des motifs dans les zones homogènes.
- identification des zones homogènes avec un détecteur de bords.
- Application d'un filtre moyenneur dans ces zones.
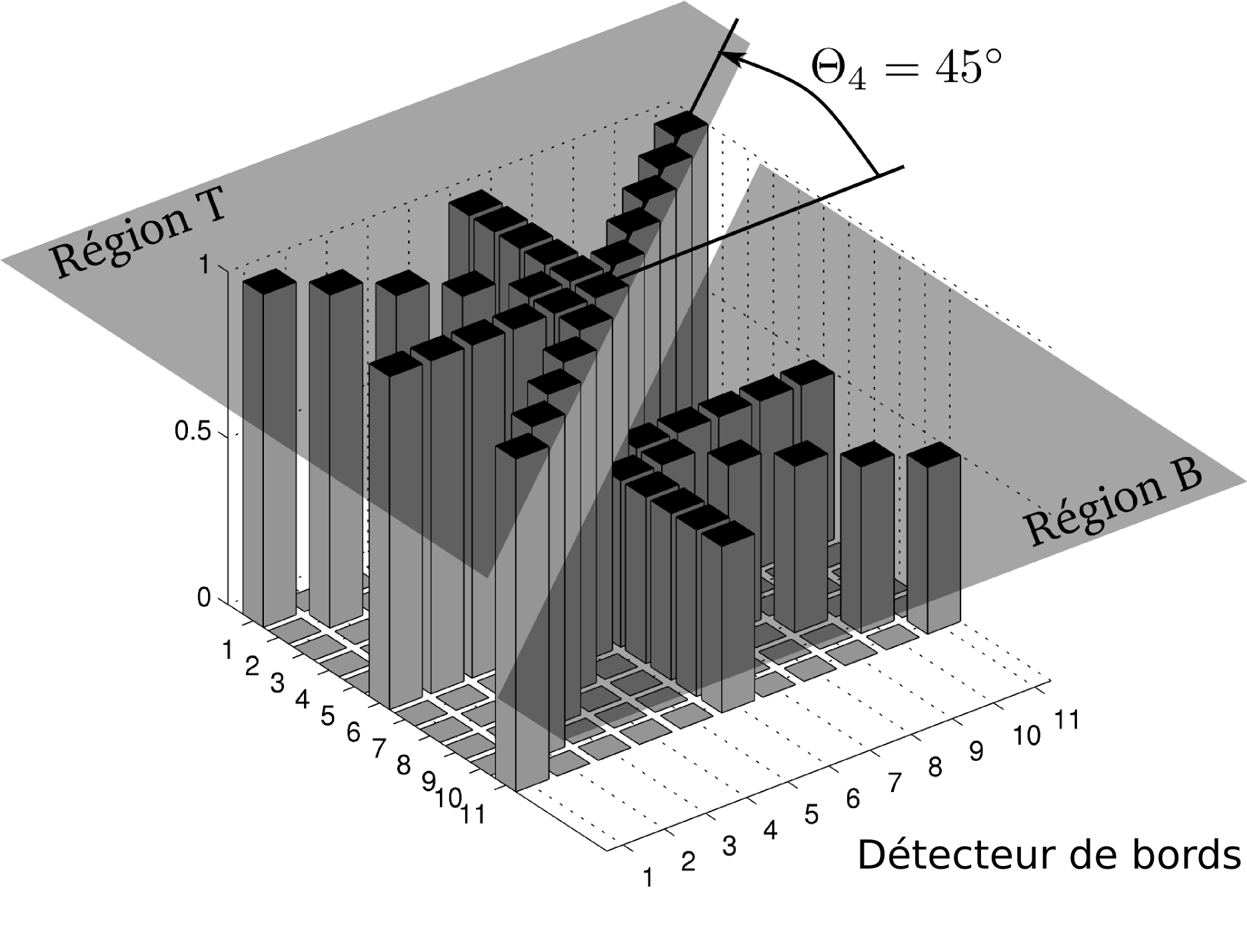
- Sous-ensembles de pixels n'ayant pas d'intersection --> MV
- Utilisation des motifs des segments pour gain de temps.
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Résultats
Sur l'ensemble d'images de S. Lansel (DenoiseLab, Université Stanford)
- Amélioration moyenne du rapport Signal sur bruit: +7,1 dB
- Indice de similarité structurelle : +30%
- Temps de calcul : 7 ms
Comparaison avec BM3D
- Amélioration moyenne du rapport Signal sur bruit: +9,5 dB
- Indice de similarité structurelle : +36%
- Temps de calcul : 4300 ms
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
 |  | |
Bruit gaussien \(\sigma=25\) | Moyennage 5x5 | |
 |  | |
PI-PD | BM3D |
LE FILTRAGE DES IMAGES
Filtre par recherche des lignes de niveaux
Synthèse - conclusion
- Rapport qualité/temps élevé.
- Traitement d'images HD à 20 fps.
- Artefacts en marche d'escalier. Réduits par la méthode de Buades et al. (+1 dB, +0,2 ms pour 512x512).
- Extension aux images couleurs et autres types de bruits (multiplicatif).
- Algorithme original sans implémentation de référence séquentielle. Conception GPU dès l'origine.
CONCLUSION GÉNÉRALE - PERSPECTIVES
- Trois types de conception mis enœuvre.
- Le portage efficace d'algorithme peut s'avérer très complexe, voire sans intérêt.
- L'emploi de la mémoire partagée n'apporte pas les meilleures performances en cas de recouvrements.
- L'écriture de code performant est fastidieuse et les codes non paramétriques.
- Création d'un programme générateur.
- Beaucoup de traitements peuvent bénéficier des techniques proposées.
- Les évolutions de l'architecture laissent entrevoir de nouvelles possibilités.
- Extension à d'autres domaines.
- certaines ardeurs ont été refroidies